


텍스트 전처리 정규화


- 문장 토큰화 : ' . '을 기준으로 문장을 나눈다.
- 단어 토큰화 : ' ' (띄어쓰기) 기준으로 단어를 나눈다.
- n-gram : uni-gram, bi-gram, tri-gram, n이 4 이상일 때는 gram 앞에 그대로 숫자를 붙여서 명명합니다.
- Stopwords 제거 : stopwords : 조사, 관사 등 텍스트 분석적으로 큰 의미가 없는 단어들
- Stemming과 Lemmatization
● Stemming(어간 추출)
- working -> work
● Lemmatization(표제어 추출)
- am, are, is -> be동사
- 어간 추출과는 달리 단어의 형태가 적절히 보존되는 양상을 보이는 특징이 있다.
- 품사를 활용하면 더 정확한 lemmatize를 뽑을 수 있다. (ex) 'v')
※ verb : 동사,
adjective : 형용사
noun : 명사
pronoun : 대명사
conjunction : 접속사
adverb : 부사
...
BOW 텍스트 피처 백터화
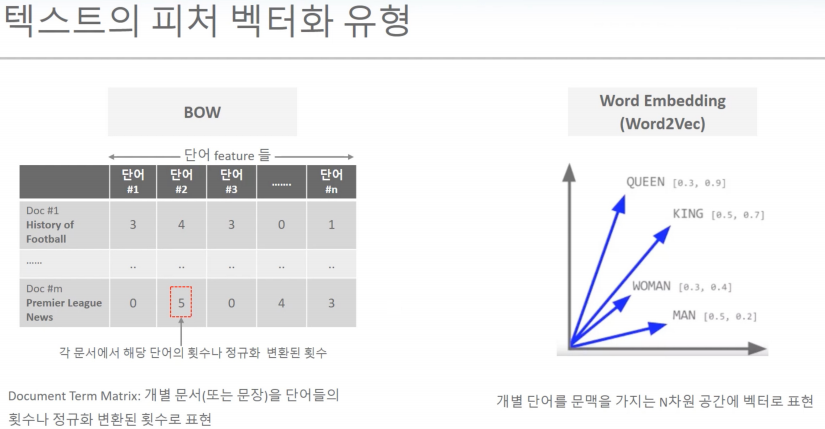

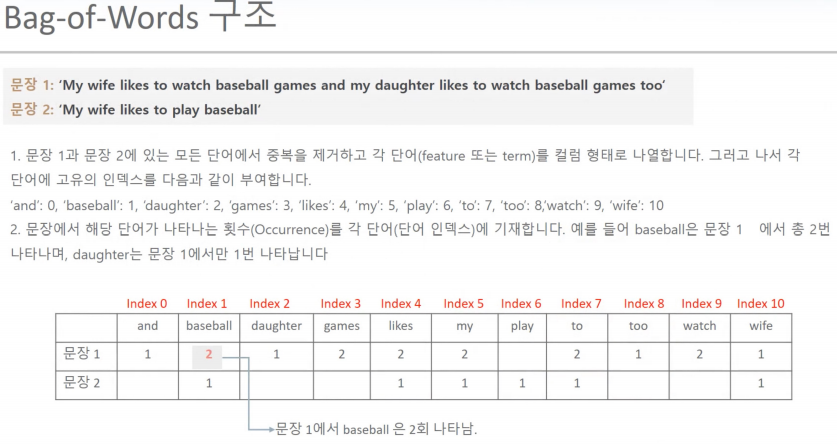
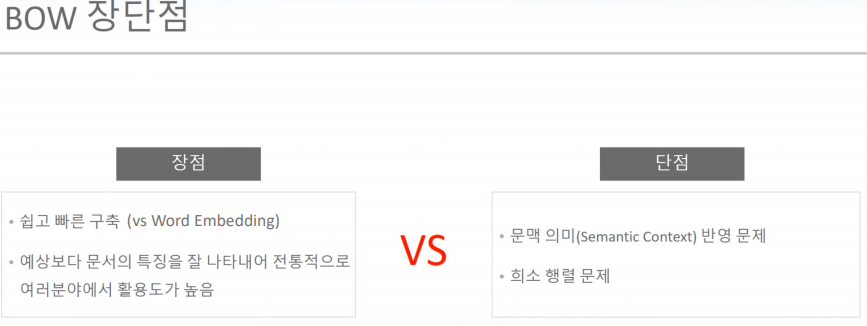






희소분석




'파이썬 (쥬피터) [2021.04.22] > 12일차' 카테고리의 다른 글
| 파이썬 12일차 - 머신러닝 예제 (감성분석) (0) | 2021.05.12 |
|---|---|
| 파이썬 12일차 - 머신러닝 개념정리 (감성분석) (0) | 2021.05.12 |
| 파이썬 12일차 - 머신러닝 예제 (데이터분류) (뉴스그룹분류) (0) | 2021.05.12 |
| 파이썬 12일차 - 텍스트분석 예제 (전처리,BOW,최소행렬) (0) | 2021.05.12 |