

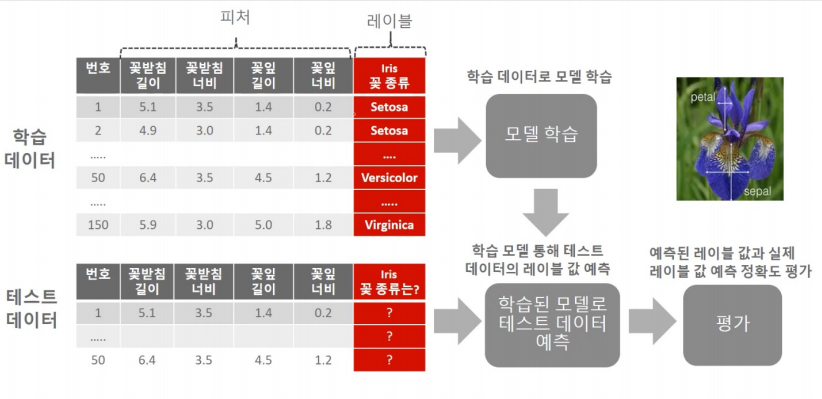
from sklearn.datasets import load_iris # iris 데이터 로드 사이킥런 안에 있는 데이터
from sklearn.tree import DecisionTreeClassifier # 의사결정나무 분류기
from sklearn.model_selection import train_test_split # 학습,테스트 데이터 분리- 변수 = load_iris() : 사이킷런에 있는 iris 데이터를 사용 하기 위해서는 객체를 만들어줘야 한다
- 변수 = iris.data : 피쳐(내용) 데이터를 가져온다
- 변수 = iris.target : 레이블(결정값) 데이터를 가져온다
- iris.target_names : iris 리이블 명을 가져온다
- DataFrame으로 변환하면 보기 편하다
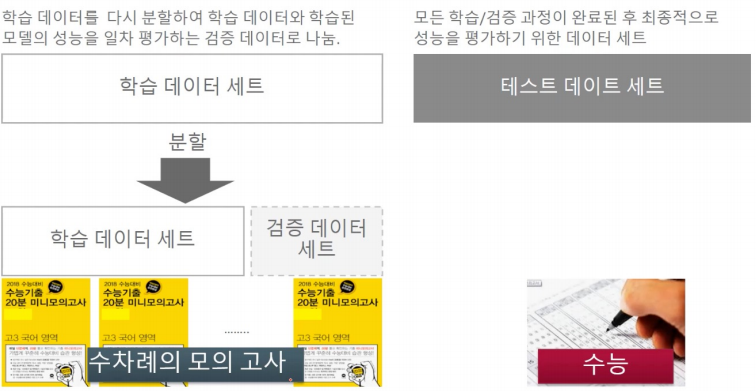
학습데이터와 테스트 데이터 세트로 분리
# test_size : 데이터 분리 값 학습:테스트 주로 8:2, 7:3으로 사용 학습이 많을 수록 정교한 값이 나옴
# random_state : 랜덤값 고정
# train_test_split() 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_label,
test_size=0.2, random_state=11)# 학습 데이터 세트
print(X_train.shape)
print(y_train.shape)
# 테스트 데이터 세트
print(X_test.shape)
print(y_test.shape)
학습데이터 세트로 학습(train) 수행
- 변수1 = DecisionTreeClassifier(random_state=11) : DecisionTreeClassifier 객체 생성
- 변수1.fit(X_train, y_train) : 학습 수행
테스트 데이터 세트로 예픅 수행
변수2 = 변수1.predict(X_test) : 학습이 완료된 DecisionTreeClassifier 객체에서 테스트 데이터 세트로 예측 수행
예측 정확도 평가
from sklearn.metrics import accuracy_score
print('예측 정확도: {0:.4f}'.format(accuracy_score(y_test,pred)))-> 93%의 정확도로 iris 데이터의 품종을 예측함.
-> 학습값이 높다고 무조건 정확도가 좋은 건 아님
-> test_size, random_state 값을 조정함에 따라 예측 정확도가 달라진다
-> 예측 값이 100%는 학습값을 그대로 받은 값이기에 예측으로 볼 수 없다 90중반~후반이 가장 좋음




- iris_data.keys() : 붓꽃 데이터 세트의 키를 보여줌
- 키는 보통 data, target, target_name, feature_names, DESCR로 구성돼 있습니다. 개별 키가 가리키는 의미는 다음과 같습니다.
- data는 피처의 데이터 세트를 가리킵니다.
- target은 분류 시 레이블 값, 회귀일 때는 숫자 결괏값 데이터 세트입니다..
- target_names는 개별 레이블의 이름을 나타냅니다.
- feature_names는 피처의 이름을 나타냅니다.
- DESCR은 데이터 세트에 대한 설명과 각 피처의 설명을 나타냅니다.
- iris_data.feature_names : 피쳐(내용)에 해당하는 이름을 보여줌
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']


# 학습/테스트 데이터 분리
from sklearn.model_selection import train_test_split
# 교차 검증
from sklearn.model_selection import KFold학습 데이터로 잘못된 예측 케이스와 테스트 데이터로 제대로 된 예측
- 실전예제 참고
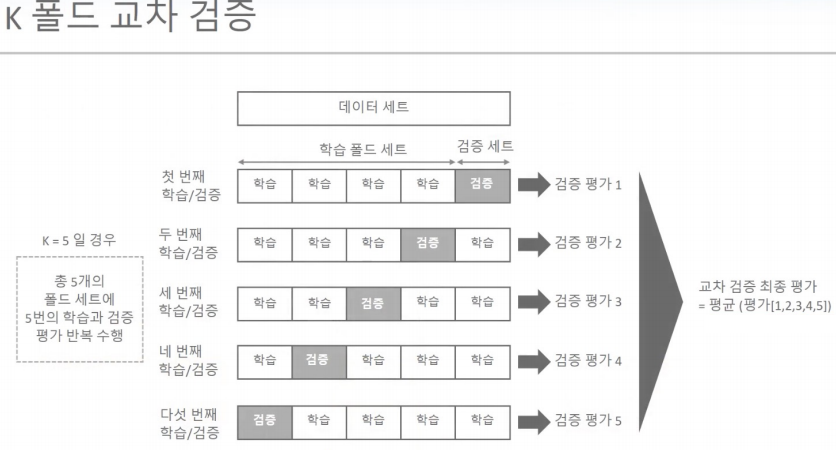
교차검증
K폴드

from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score # 학습 정확도 측정
from sklearn.model_selection import KFold # 일반 k폴드
import numpy as np
# 데이터 로드
iris = load_iris()
label = iris.target
features = iris.data- 변수 = DecisionTreeClassifier(random_state=156) : 모델 정의
- cv(cross validation) : 교차검증
- 변수 = KFold(n_splits=n) : n개의 폴드 세트로 분리하는 KFold 객체와 폴드 세트별 정확도를 담을 리스트 객체 생성
- cv_accuracy = [] : 최종적으로는 n번의 교차검증의 평균 정확도 계산
- 변수.split(features) : for문이 도는 동안 generator가 kfold된 데이터의 학습, 검증 row 인덱스를 array로 반환
# KFold객체의 split( ) 호출하면 폴드 별 학습용, 검증용 테스트의 row 인덱스를 array로 반환
for train_index, test_index in kfold.split(features):
# kfold.split( )으로 반환된 인덱스를 이용하여 학습용, 검증용 테스트 데이터 추출
X_train, X_test = features[train_index], features[test_index]
y_train, y_test = label[train_index], label[test_index] # 학습 및 예측
dt_clf.fit(X_train , y_train)
pred = dt_clf.predict(X_test)
n_iter += 1 # 반복 시 마다 정확도 측정
accuracy = np.round(accuracy_score(y_test,pred), 4) # 정확도 : 소수점 4자리까지 구함
train_size = X_train.shape[0]
test_size = X_test.shape[0]
print('\n#{0} 교차 검증 정확도 :{1}, 학습 데이터 크기: {2}, 검증 데이터 크기: {3}'
.format(n_iter, accuracy, train_size, test_size))
print('#{0} 검증 세트 인덱스:{1}'.format(n_iter,test_index))
cv_accuracy.append(accuracy)# 개별 iteration별 정확도를 합하여 평균 정확도 계산
print('\n## 평균 검증 정확도:', np.mean(cv_accuracy))
Stratified K 폴드
- KFOLD 교차검증의 문제점 : 불균형한 데이터에는 적용이 안된다.
이를 해결할 방법이 StratifiedKFold : 불균형한 분포도를 가진 레이블 데이터 집합을 균형하게 섞어주고 교차검증을
진행한다.
from sklearn.model_selection import StratifiedKFold
# StratifiedKFold 클래스의 인스턴스 선언 : skf
skf = StratifiedKFold(n_splits=3)
n_iter=0
# StratifiedKFold 사용시 KFold와 차이점 : 레이블 값을 넣어줘서 레이블에 맞게 균일하게 분포를 맞춰준다.
for train_index, test_index in skf.split(iris_df, iris_df['label']):
n_iter += 1
label_train= iris_df['label'].iloc[train_index]
label_test= iris_df['label'].iloc[test_index]
print('## 교차 검증: {0}'.format(n_iter))
print('학습 레이블 데이터 분포:\n', label_train.value_counts())
print('검증 레이블 데이터 분포:\n', label_test.value_counts(), '\n')-> StratifiedKFold 했더니 균일하게 학습 레이블, 검증 레이블이 들어가 있으므로 검증이 제대로 된다!
-> StratifiedKFold는 각 레이블에 해당하는 피쳐의 자료들을 섞어서 확실하게 확률을 학습하고 예측한다
cross_val_score( ) : 교차검증을 보다 간편하게

- 폴드 세트 추출, 학습 및 예측, 평가 과정들을 한번에 수행
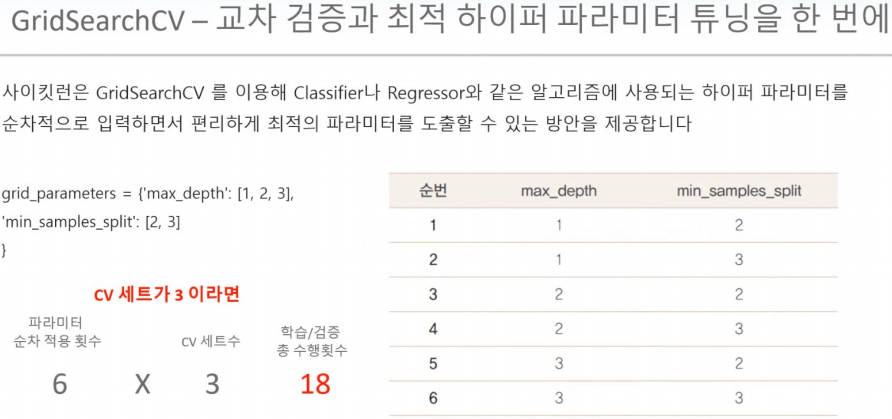
GridSearchCV : 교차 검증 + 하이퍼 파라미터 튜닝 (중요)
- 하이퍼 파라미터 : 모델의 성능을 최대로 끌어올리는 학습 조건
- 하이퍼 파라미터 튜닝의 중요성 : 학습 조건을 잘 설정해야 최대의 성능을 내는 머신러닝 모델을 얻을 수 있다.
- 변수 = {'max_depth':[1, 2, 3], 'min_samples_split':[2,3]} : hyper-parameter 들을 딕셔너리 형태로 설정
- 변수1 = GridSearchCV(dtree, param_grid=parameters, cv=3, refit=True, return_train_score=True)
: param_grid의 하이퍼 파라미터들을 3개의 train, test set fold 로 나누어서 테스트 수행 설정,
refit=True 가 default : 가장 좋은 파라미터 설정으로 재 학습 시킴.
- 변수1.fit(X_train, y_train) : 붓꽃 Train 데이터로 param_grid의 하이퍼 파라미터들을 순차적으로 학습/평가.
<
- 변수2 = pd.DataFrame(grid_dtree.cv_results_)
변수2[['params', 'mean_test_score', 'rank_test_score', 'split0_test_score', 'split1_test_score', 'split2_test_score']]
: GridSearchCV 결과는 cv_results_ 라는 딕셔너리로 저장됨 이를 DataFrame으로 변환해서 확인
-> 가장 좋은 hyper-parameter는 {'max_depth': 3, 'min_samples_split': 3}
>
- 변수1.cv_results_ : GridSearchCV 결과 전체 확인
- 변수1.best_params_ : 최적 파라미터
- format(변수1.best_score_) : 최고 정확도
- 변수3 = 변수1.predict(X_test)
format(accuracy_score(y_test, 변수3) : 테스트 데이터 예측 정확도 확인
: refit=True로 설정된 GridSearchCV 객체가 fit()을 수행 시 학습이 완료된 Estimator를 내포하고 있으므로 predict()를
통해 예측도 가능
- estimator 종류
1. 분류 : DecisionTreeClassifier, RandomForestClassifier, ...
2. 회귀 : LinearRegression, ...
- 변수4 = 변수1.best_estimator_ : GridSearchCV의 refit으로 이미 학습이 된 estimator 반환
위에서 변수 = DecisionTreeClassifier() 로 estimator를 선언했고, 이를 GridSearchCV에 넣었으므로,
- 변수5 = 변수4..predict(X_test) : GridSearchCV의 best_estimator_는 이미 최적 하이퍼 파라미터로 학습이 됨,
데이터 세트 정확도
- GridSearchCV를 사용했더니 교차검증을 통해 최적의 모델 성능을 내는 하이퍼 파라미터 튜닝을 했다.
즉, 정확도가 높은 모델을 얻었다!
데이터 전처리
- 결손 값 처리, 데이터 인코딩, 데이터 스케일링, 이상치 제거, feature 선택 추출 및 가공
*데이터 인코딩
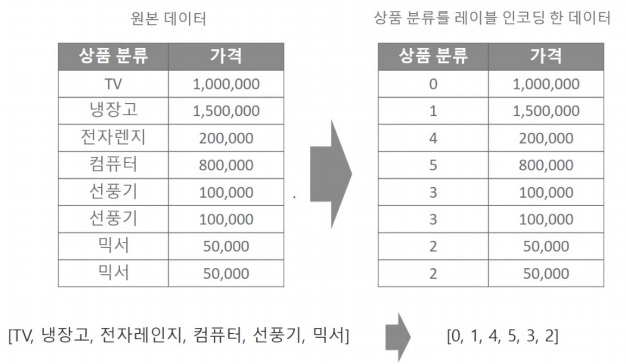
레이블 인코딩
- 변수3 = ['TV','냉장고','전자렌지','컴퓨터','선풍기','선풍기','믹서','믹서']
- 변수1(객체) : LabelEncoder() : 레이블인코더 클래스를 객체로 생성
- 변수1.fit(변수3) : transform()을 수행하기 전 틀을 맞춰주는 역활
변수2 = 변수1.transform(변수3) : 레이블 인코딩 수행
- encofer.classes_ : 인코딩 클래스 ('TV','냉장고','전자렌지','컴퓨터','선풍기','선풍기','믹서','믹서')
- encoder.inverse_transform([0, 1, 4, 5, 3, 3, 2, 2]) : 각 클래스 안에 번호를 지정해준다
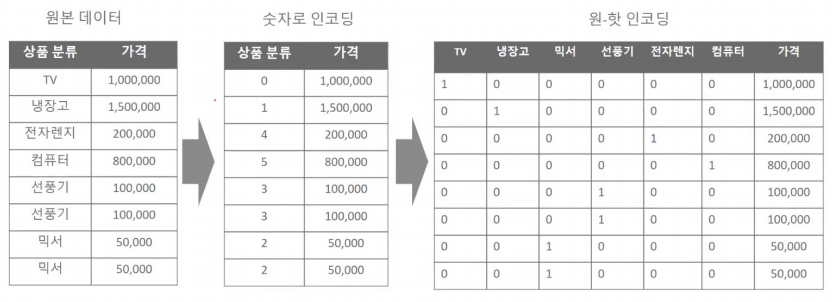
원 핫 인코딩
- <sklearn에서의 원핫 인코딩은 좀 복잡하다>
첫번째, 먼저 숫자값으로 변환을 위해 LabelEncoder로 변환합니다.
두번째, 2차원 데이터로 변환합니다. (reshape 활용)
마지막으로 원-핫 인코딩을 적용합니다.
- 실전예제 참고
판다스의 원핫 인코딩 (중요)
- 판다스의 get_dummies 함수를 이용하면 쉽게 원핫 인코딩이 가능하다
- 실전예제 참고
피쳐 스케일링 정규화


- 실전예제참고
'파이썬 (쥬피터) [2021.04.22] > 7일차' 카테고리의 다른 글
| 파이썬 7일차 - 머신러닝 예제 (데이터 전처리) (0) | 2021.05.04 |
|---|---|
| 파이썬 7일차 - 머신러닝 예제 (교차검증) (0) | 2021.05.04 |
| 파이썬 7일차 - 머신러닝 예제 (내장데이터 iris_data 구조 확인) (0) | 2021.05.04 |
| 파이썬 7일차 - 머신러닝 예제(데이터분류-붓꽃) (0) | 2021.05.04 |